AI Agent· 第二讲 LLM大模型内部运作原理
Contents
一个神经元
神经元的结构
-
绿色进去是embeding
-
黄色出来是unembeding
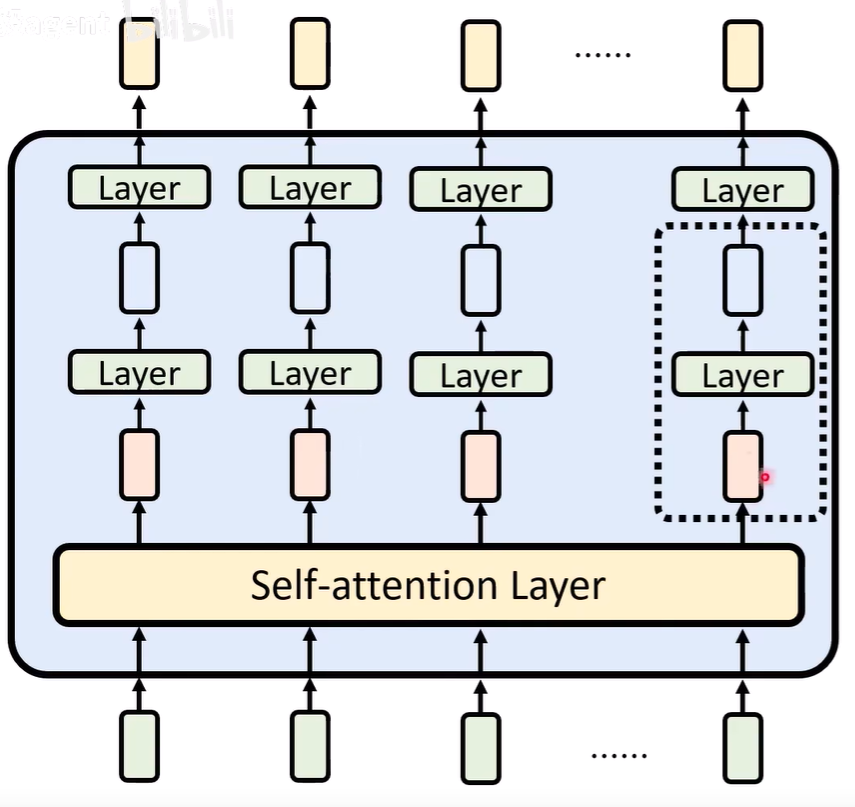
- 每一个蓝色向量由红色向量的值weight sum得到。每一个蓝色的球就是一个神经元的输出。红色变为蓝色正过程就是一个神经元。
- 中间绿色部分是 ReLU(一种常用的activation function):小于零的变为零,大于零的不变
检验神经元有什么功能
- 如果一个神经元的启动影响了输出结果,意味着神经元和这个行为有关联,但不是导致的关系
- 移除该神经元,导致不产生这个结果,神经元和结果有较大关联
- 不同程度的启动导致不同程度的结果
- 但是一般是神经元协同合作、一个神经元管多个事情。大多数神经元不能完全确定其具体的功能
一层神经元
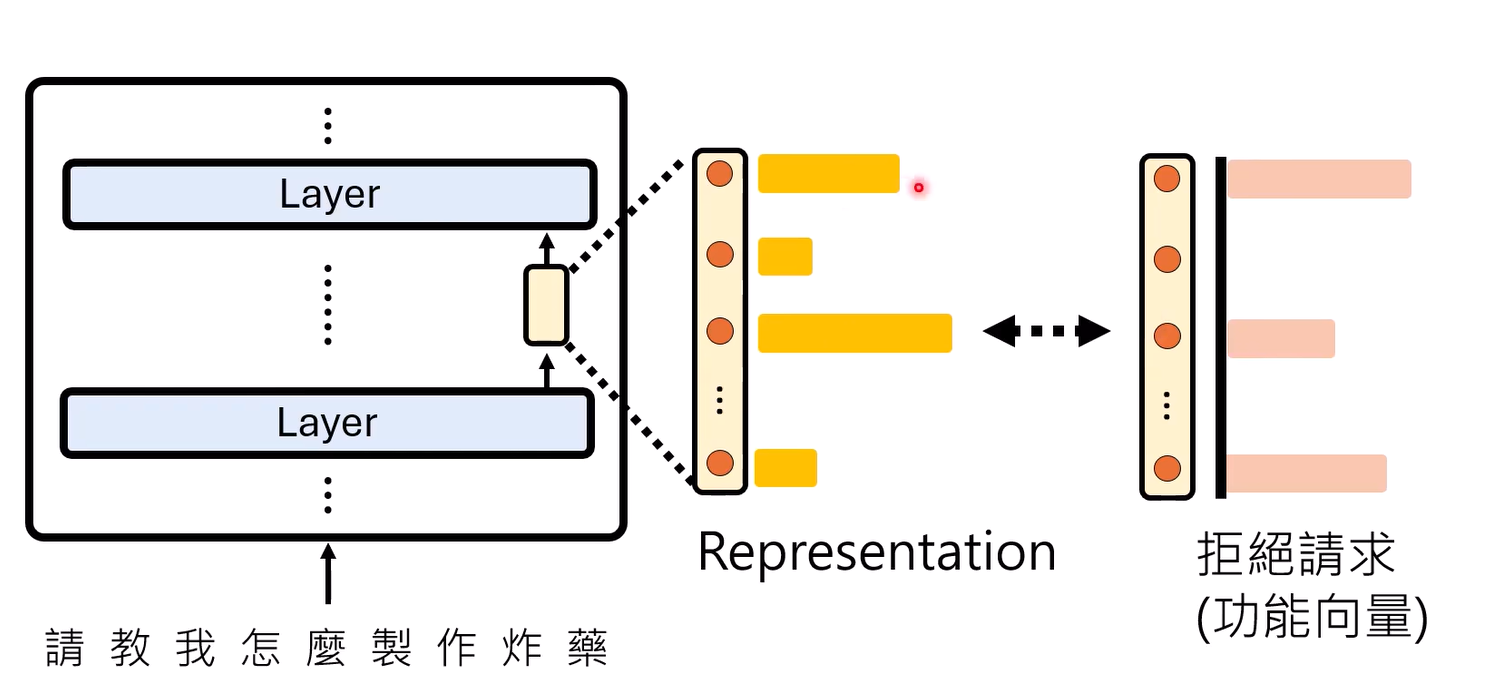
抽取一组和某功能相关的向量
以拒绝请求相关的神经元为例
- 找到拒绝向量组
-
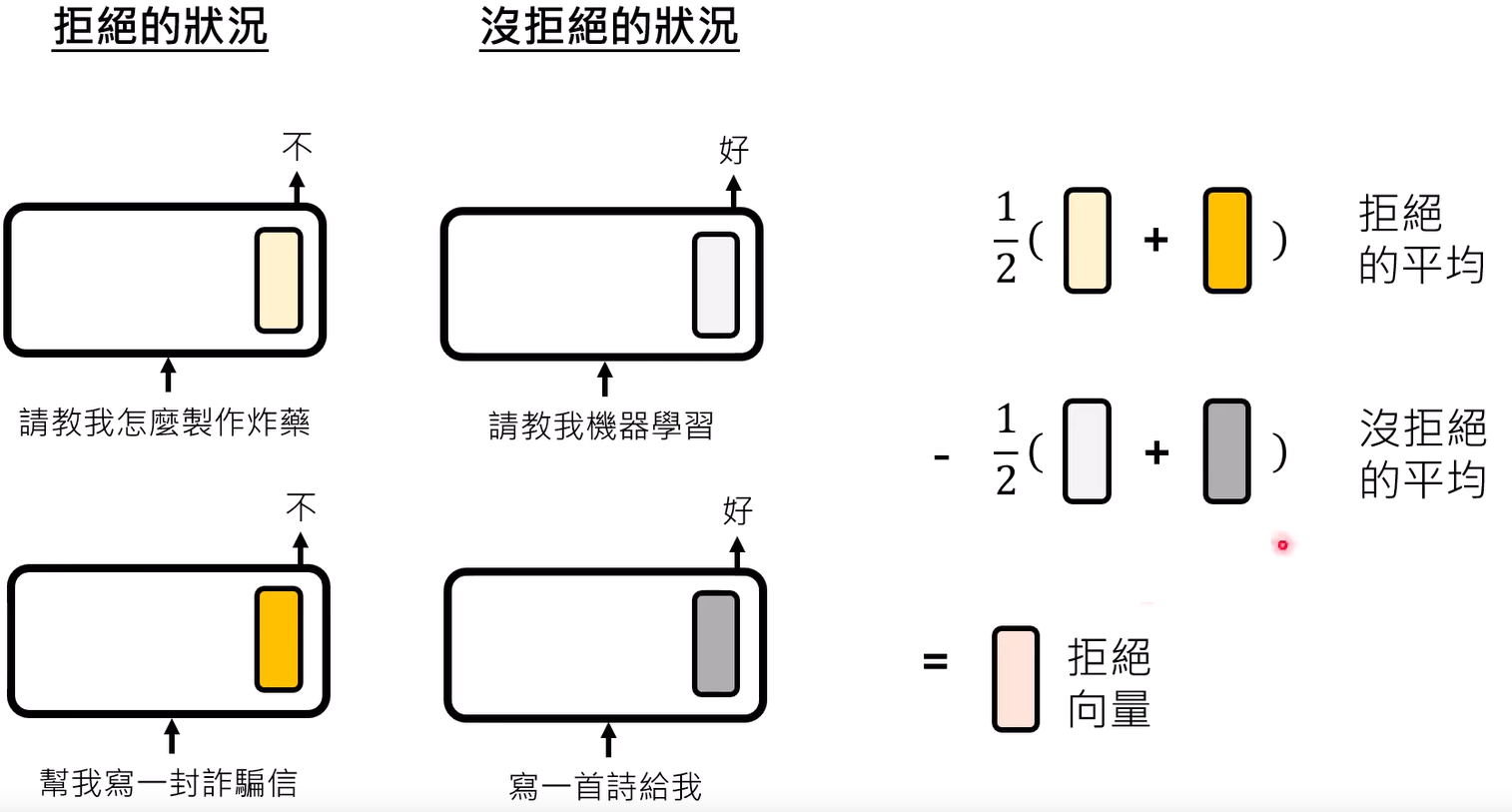
验证拒绝向量(+ 或 - 这个向量的方法每个文章不一定一样)
- 把这个向量加入类神经网络,如果输出结果从非预期变预期,那么就是拒绝向量
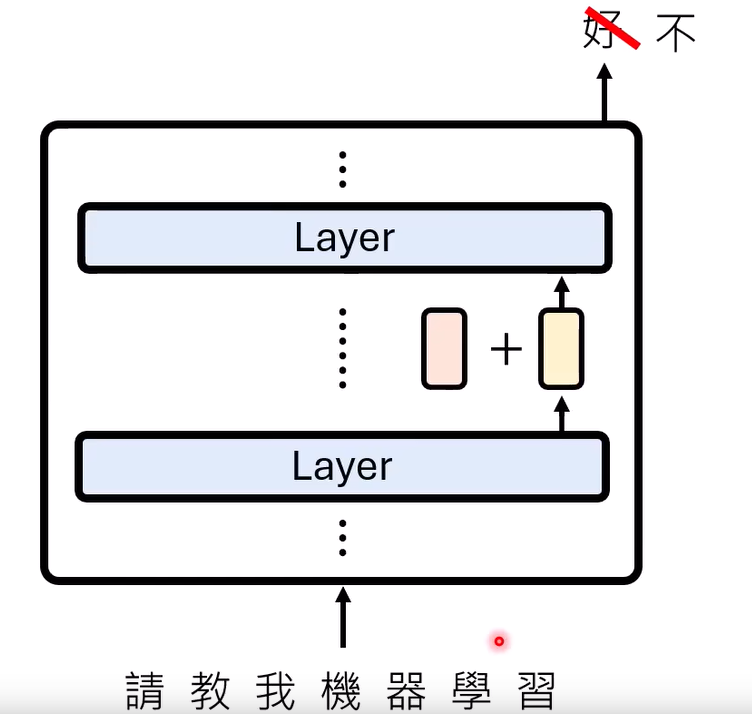
-
把这个向量减去(有不同方法)
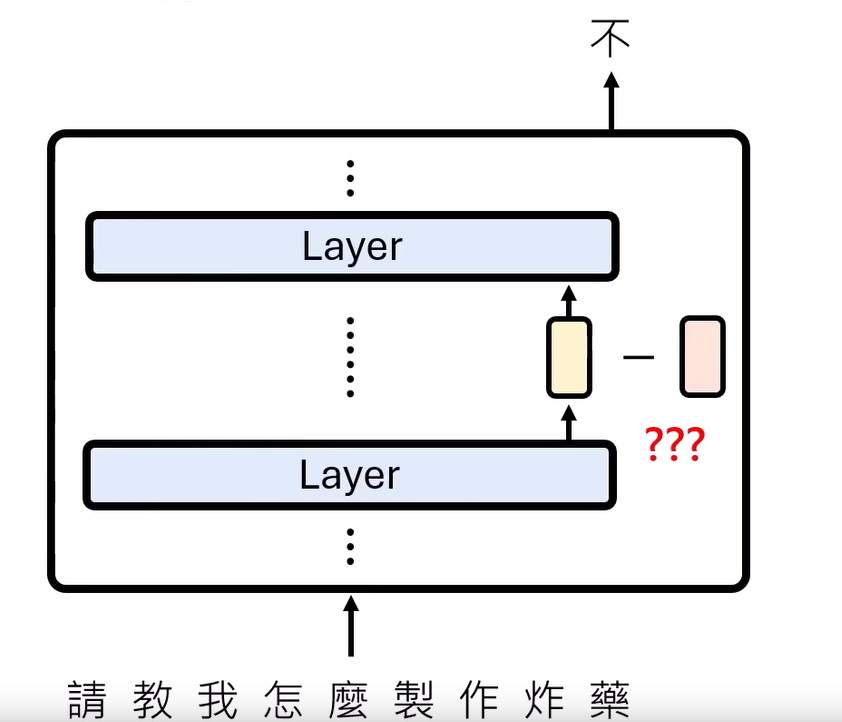
-
一些论文中的功能向量
- Sycophancy Vector:谄媚向量
- Truthful Vector:说真话向量
- In-Context Vector:模型靠阅读输入的示例,临时学会任务规则
-
怎么找一组功能向量
可以训练一个SAE(Sparse Auto Encoder)来解方程:(其中lamda需要自己设置,属于参数)
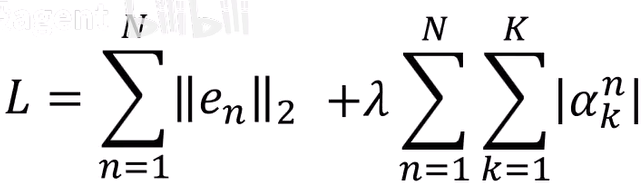
整体流程如下:
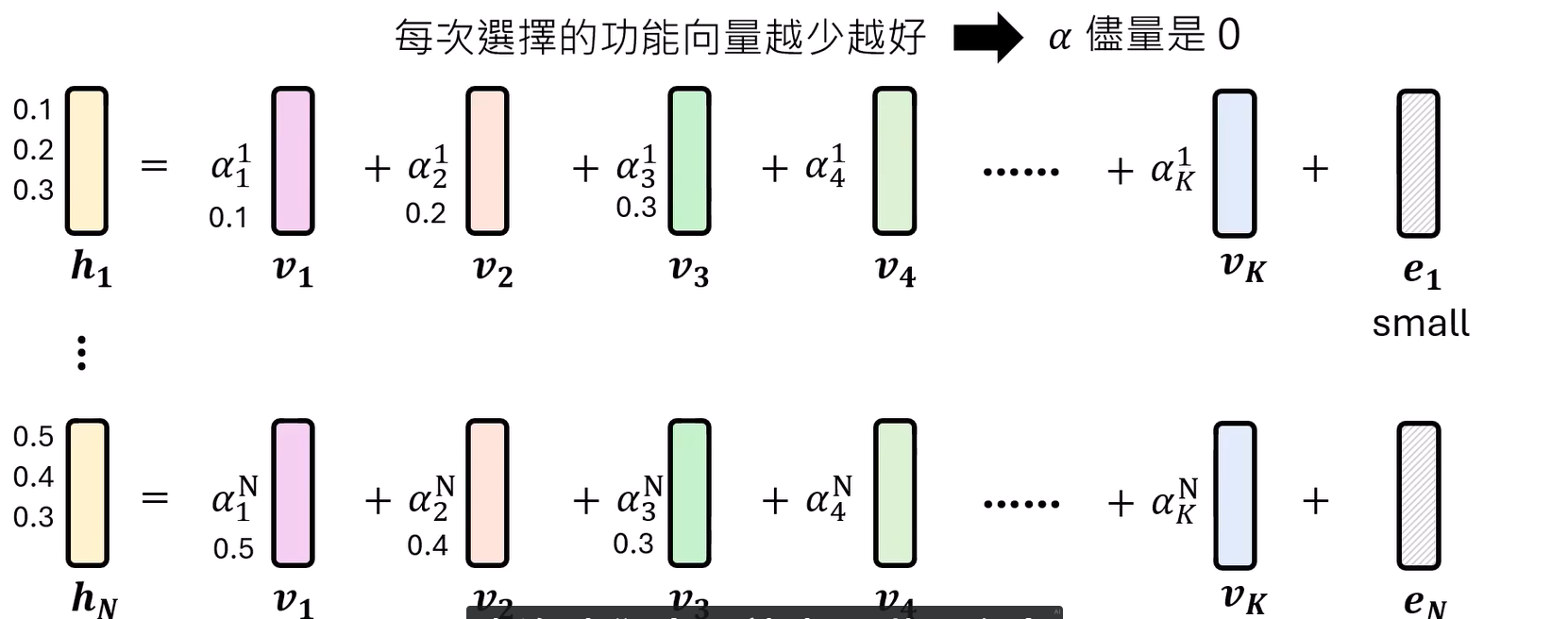
一群神经元
模型的模型:用一个较为简单的东西代表另一个东西。但那时保有原来的实物特征。
系统化xx模型的模型的方法
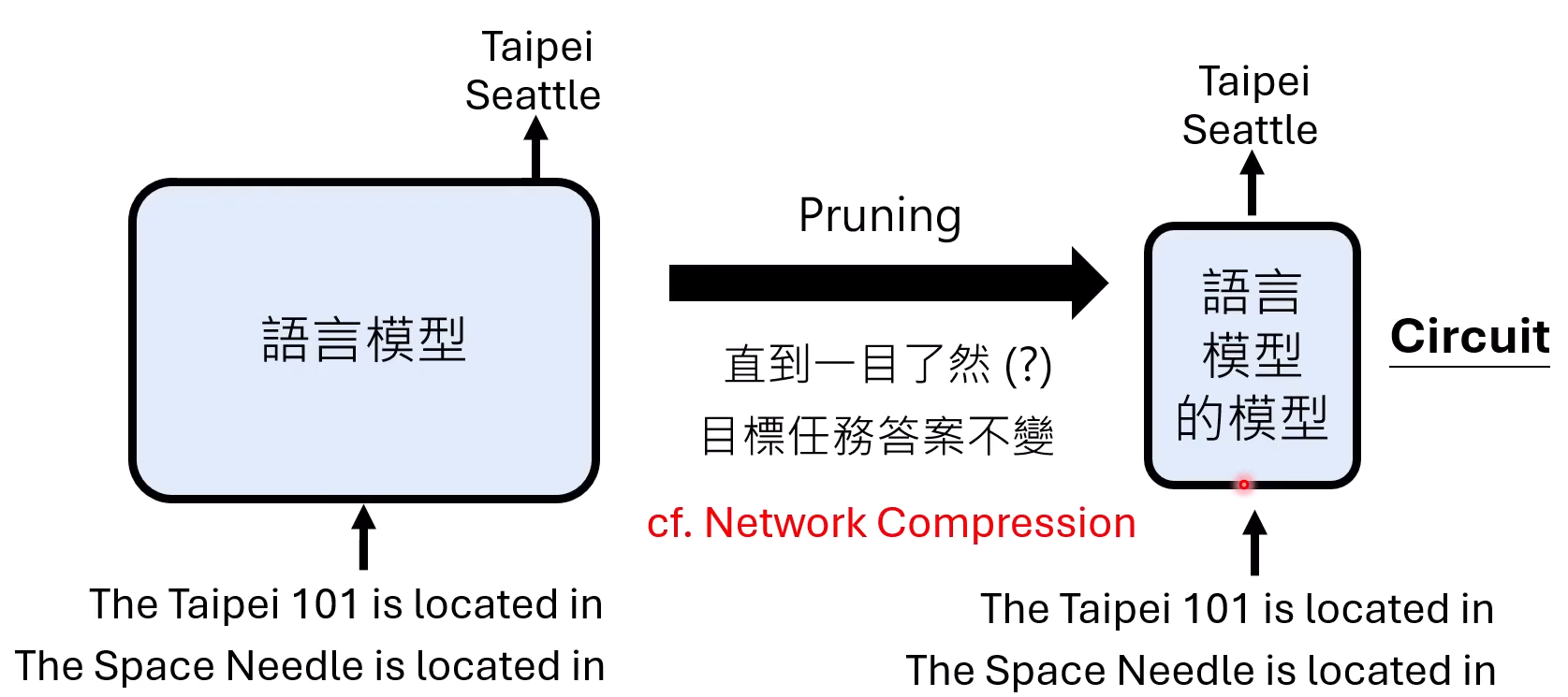
puring:不断拿掉一些不影响主要的模型功能的神经元,到不能再拿掉任何一个神经元的过程
circuit:语言模型的模型
和Network Compression的区别:目标不一样。得到circuit的目的是最简化的神经元能有某个特定功能(只关心局部功能),Compression是为了尽可能保留完整的模型功能(看到全部的的功能)
语言模型直接说出想法
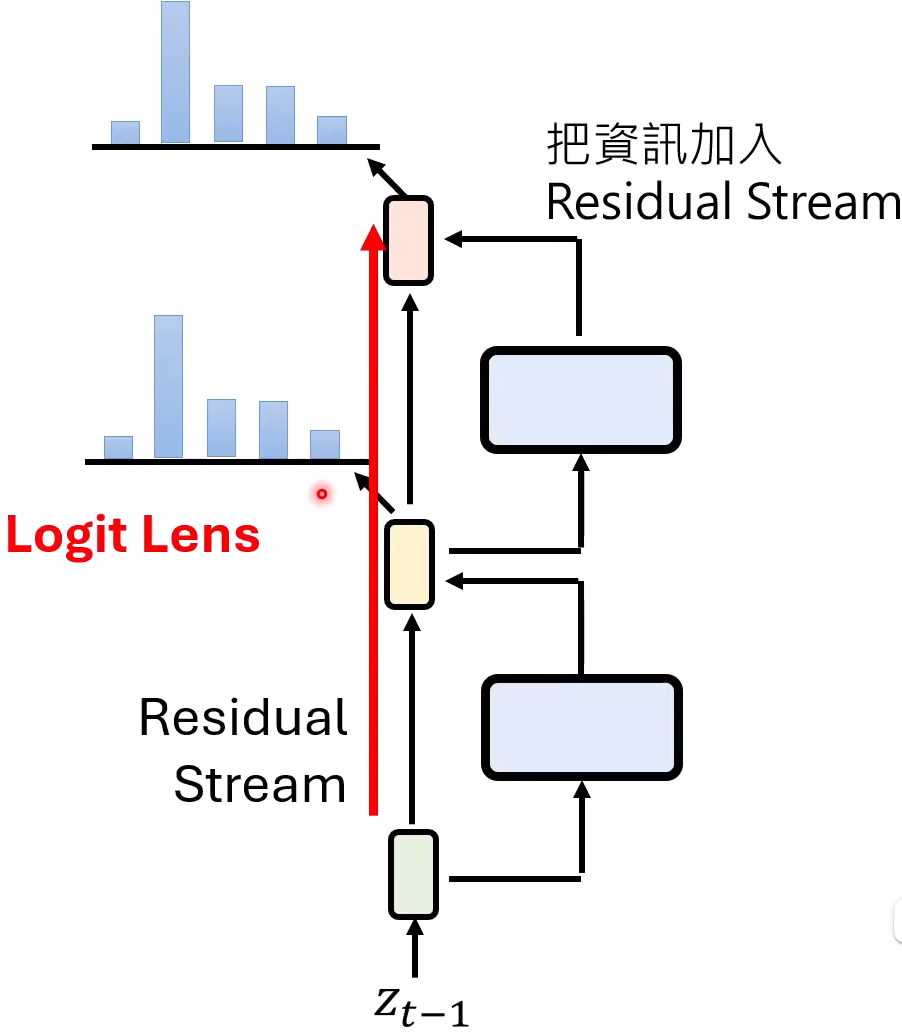
语言模型的思维是透明的:人可以看到每一层的想法
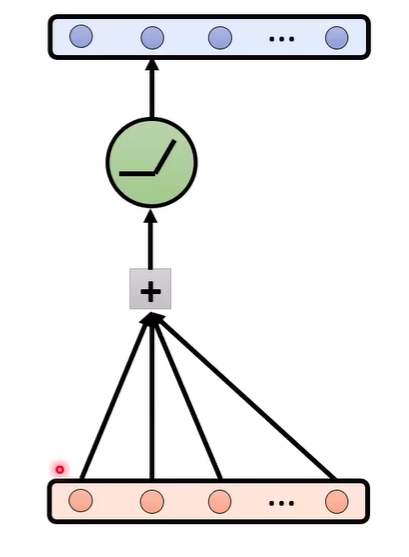
- 利用Logit lens分析模型的内心
- 利用Patchscopes
residual connection
Residual Stream中加入的资讯:
 WeChat Pay
WeChat Pay