AI Agent· 第一讲 AI Agent 原理
Contents
AI Agent工作流
-
RL(Reinforcement Learning):Learn to Maximize Reward
-
局限:要为了每一个任务用不同的RL训练模型
-
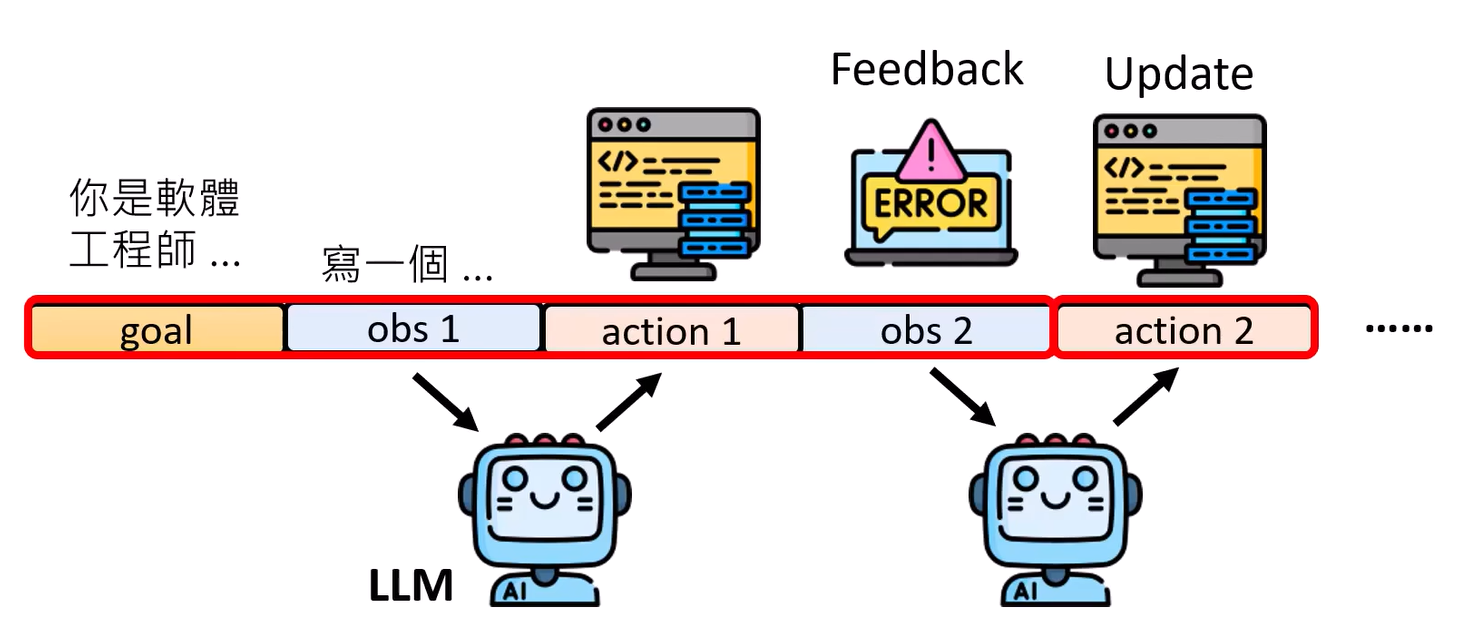
从LLM角度看Agent的问题:依靠现有的模型反复做observation和action接龙,利用LLM来连接
LLM运行AI Agent优势
- 传统 agent:只能使用事先设定好的行为,需要reward【尝试不同的值,玄】和Compile Error做回馈(alpha Go)
- LLM agent:可以对不同的action有近乎无限的回答,还可以使用工具。Compile Error通过Log传输。
AI Agent关键能力
-
根据过去经验调整行为(非调参)
不断回忆整个Agent一生记忆,但是可能会导致超常自缚式记忆/超忆症(难完成思考)
解决方案:用Read模组从Memory里面调用有用的相关经验(从database里面检索相关信息,做查询)【本质RAG】
负面的经验对实际的调整几乎没有帮助,告诉他要做什么而是不要做什么
Write:利用Write模组来选择需要放入Memory的信息(可用另一个LLM)
Reflection:把记忆中的资料重新整理(可用另一个LLM)
Knowledge graph:知识图谱,让知识查询更简单
参考论文
MemGPT、Agent Workflow Memory、A-MEM: Agentic Memory for LLM Agents
-
语言模型常用工具(Function,Function Call)
- 优先级是System Prompt更高
- 语音转文字(调用工具)再输入只可读文字的模型
- tool Selection:工具选择模组,对多个工具情况处理(把多个工具的使用存入Memory)
- LLM自己也可以写工具
- 什么样的外部知识容易说服ai:越接近本身信念差距小越容易被说服,更相信同类ai的话,更相信发布时间更新的文章
- 就算找到所有材料都对,但是也不能保证答案对
- 用工具不一定就比不用快
参考论文:TroVE, LATM,CREATOR,CRAFT

-
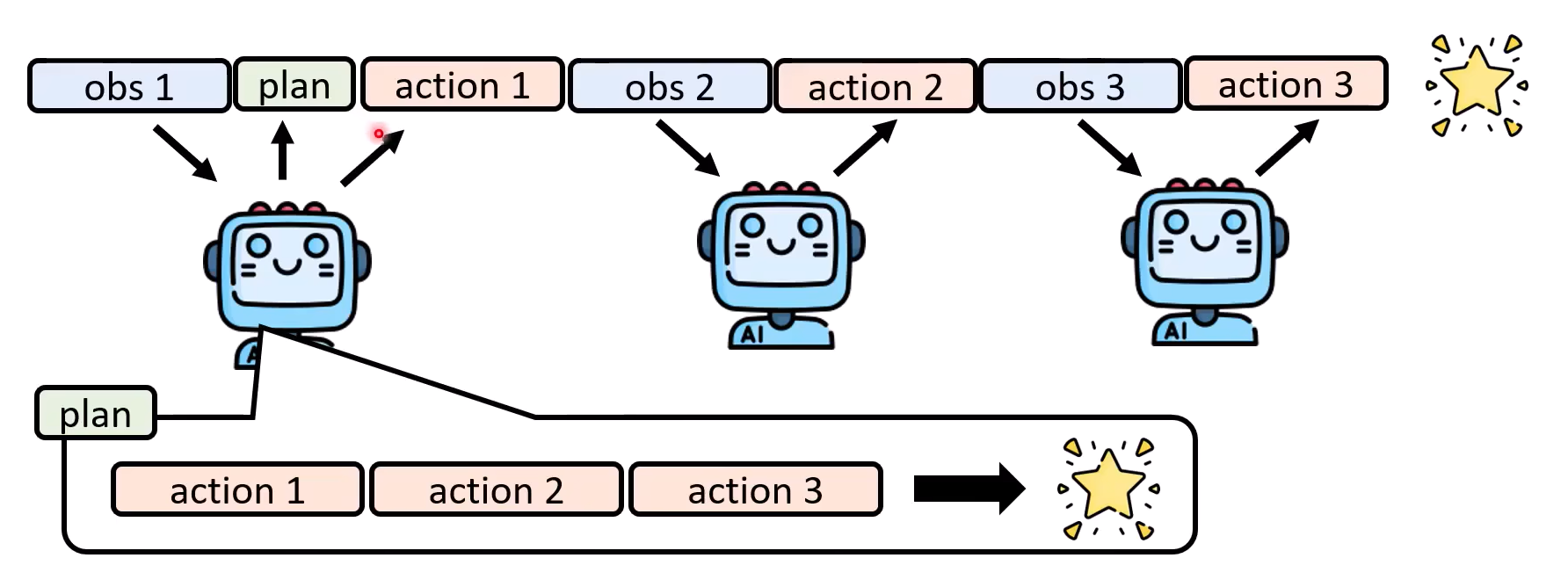
AI 能不能做计划
-
计划是不断变化的,预期不同导致原计划不行。
- 改进:每一个observation不同来改变计划
-
Benchmark
- 普通方块世界
- 神秘方块世界
-
强化AI Agent的规划能力
- 和想象环境(World Model)互动,每一条路径都尝试:对每一个新路径先判断是否有希望
-
想象的能力–Reasoning的能力(可能想太多)
想象自己做尝试,猜测结果,找到成功最佳solution
-
 WeChat Pay
WeChat Pay