AI Agent· 第三讲 Transformer架构
Contents
Transformer架构
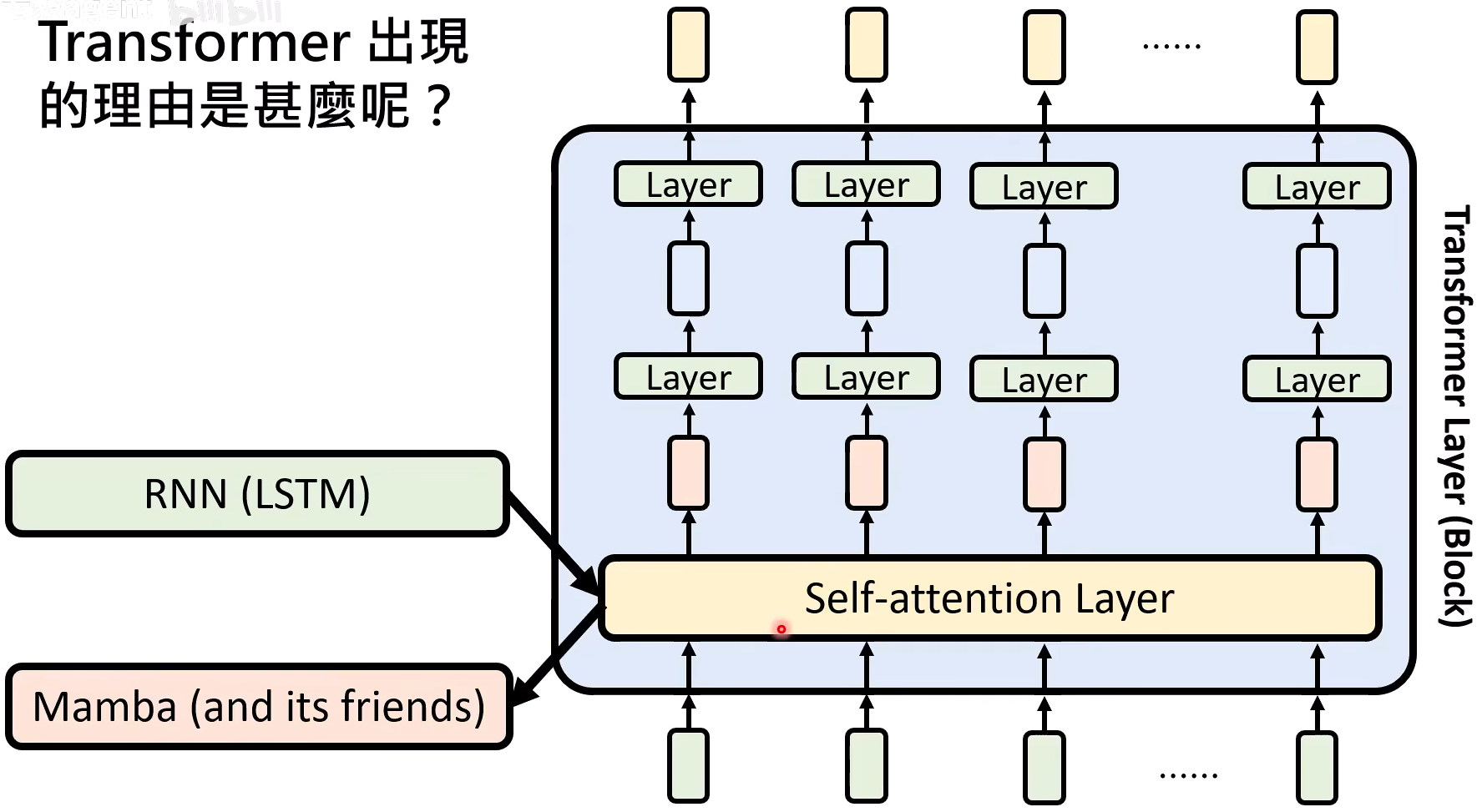
Self-Attention vs RNN
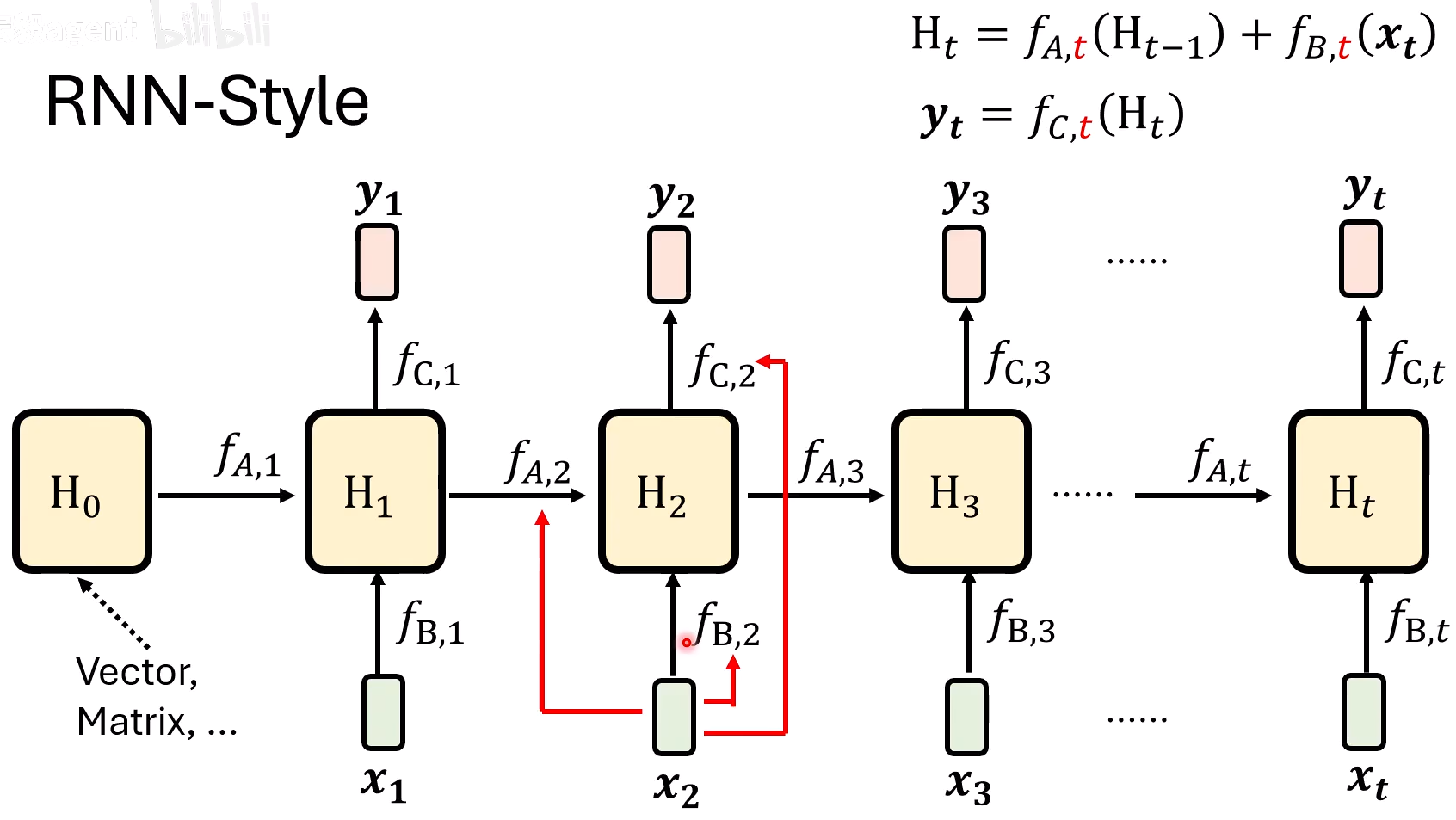
RNN(类比Memory的过程)
- Ht:memory
- f(A,t):Reflection
- f(B,t):Read
- f(C,t):Write
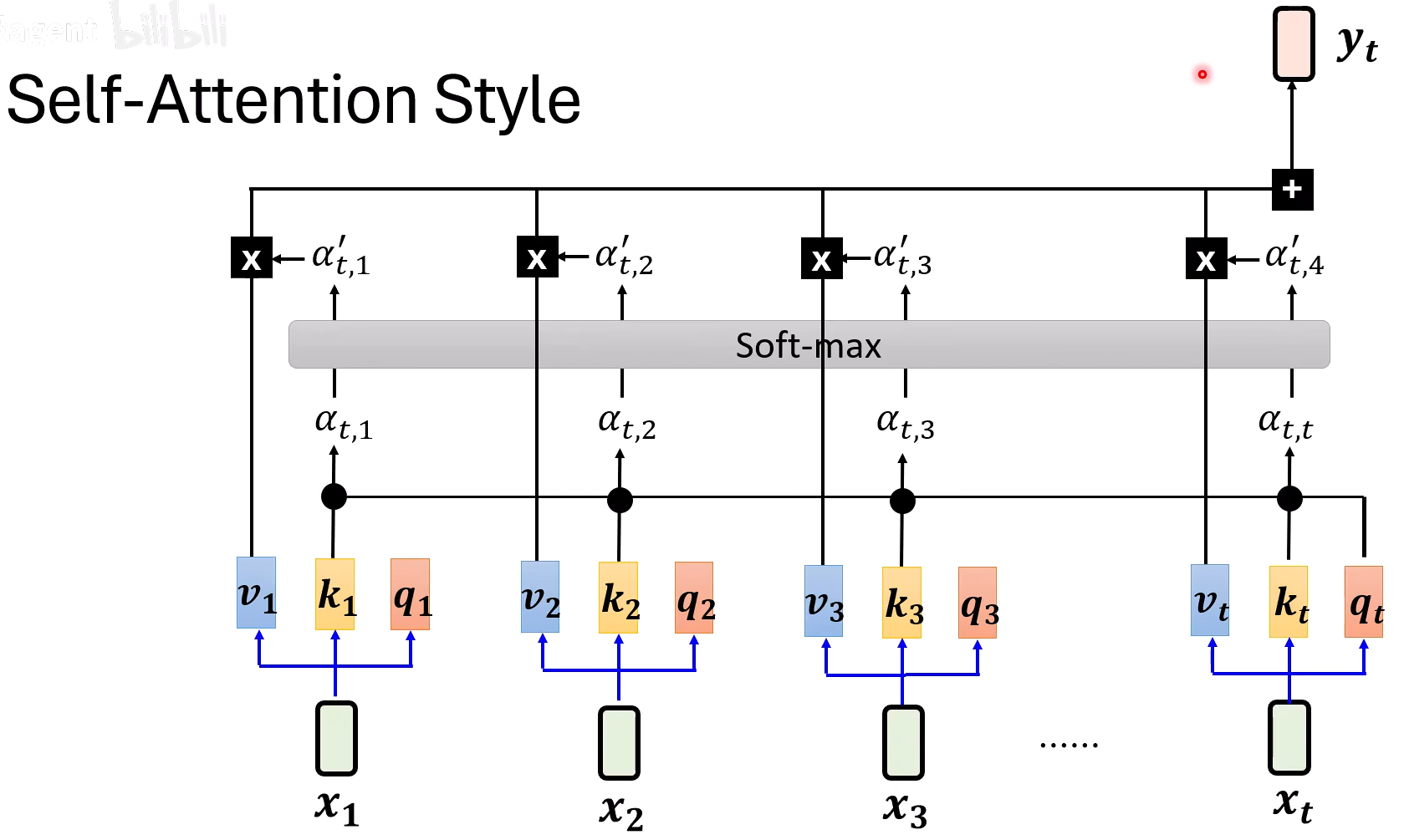
Self-Attention
二者区别
-
Self-Attention
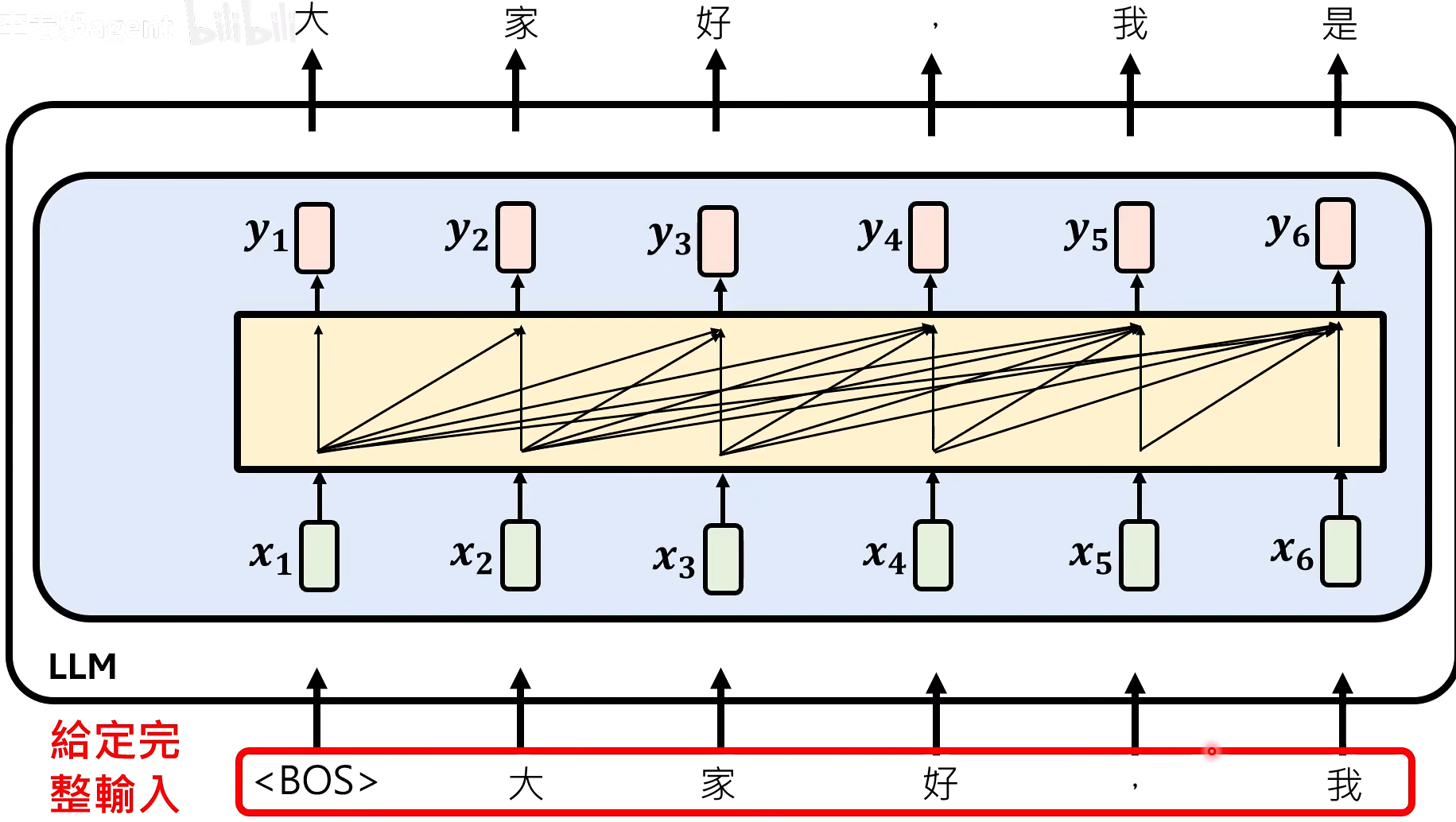
- 平行的输出结果:对于一个完整的输入,能够平行的输出对应的下一个的token。
- memory占用更多:每一个输入都依赖于前面所有的输出
- GPU友好:矩阵运算
-
RNN
- 线性的输出
Linear Attention
RNN从数学公式层面平行输出
公式上去掉了f(A,t),结构上和self-attention只差一个softmax
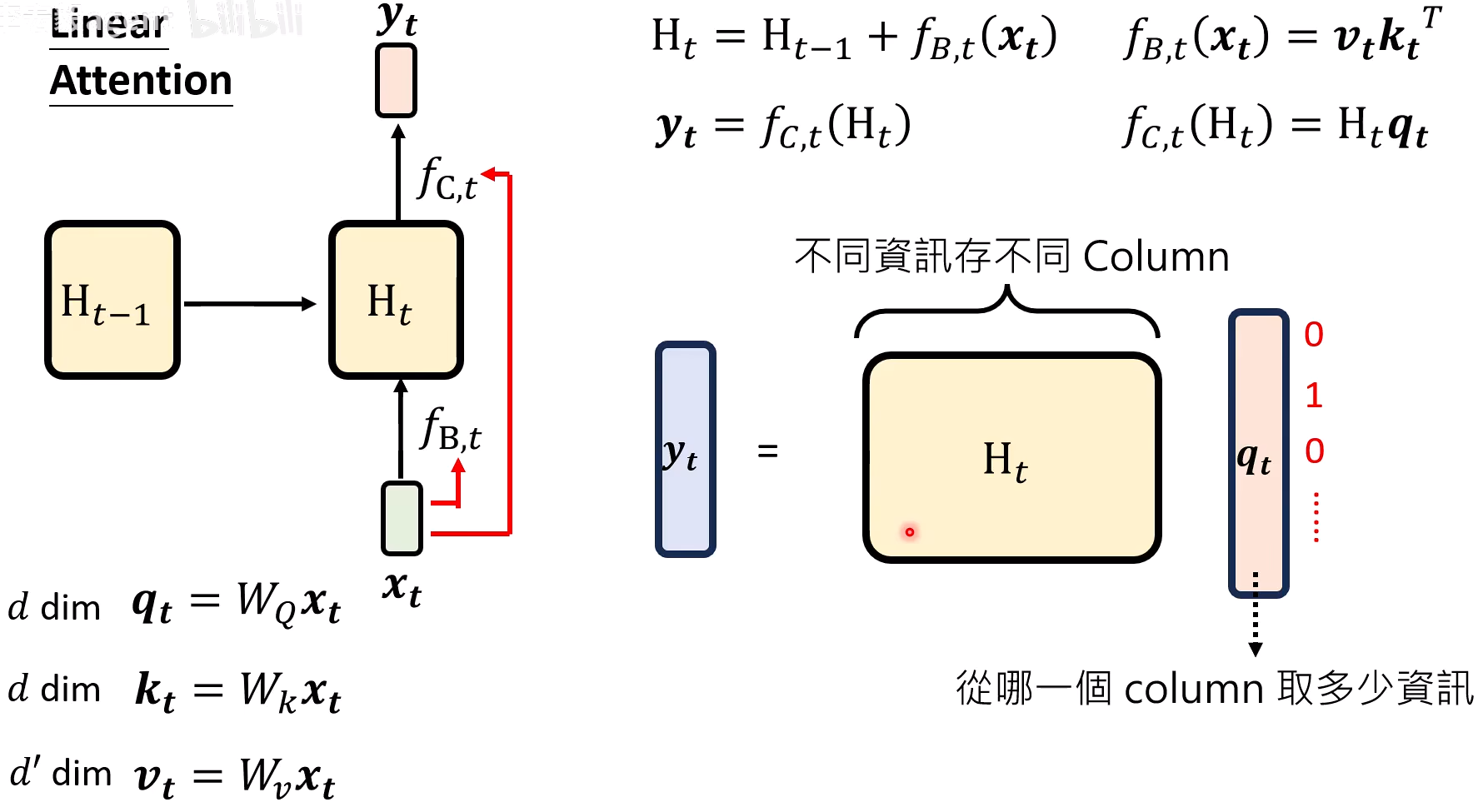
-
Training:类似self-attention
-
inference:类似RNN
-
缺点:记忆永远不改变(不会遗忘所有的内容)
-
基于Linear attention的改进模型
-
Retention Network
加入gama来控制过去的记忆逐渐遗忘
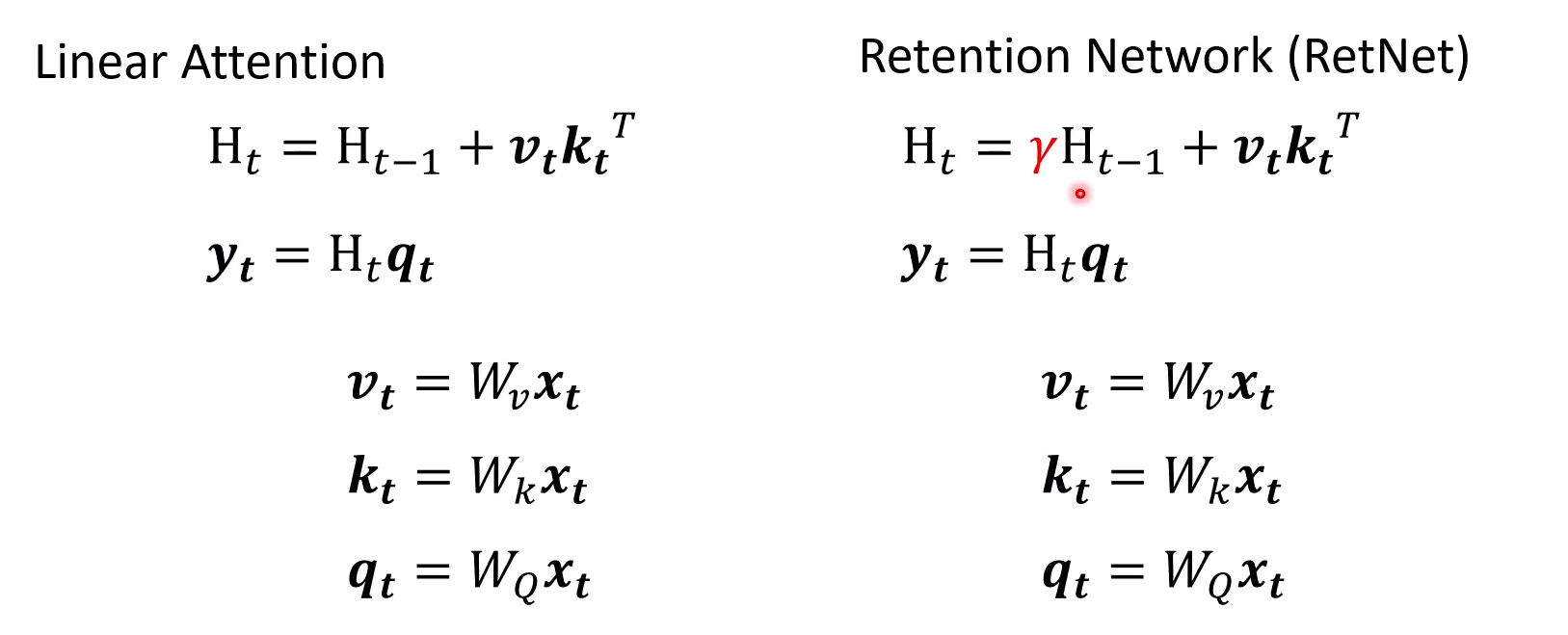
-
Gated Retention
利用sigmod来对gama值训练,对不同的记忆有不同程度的遗忘
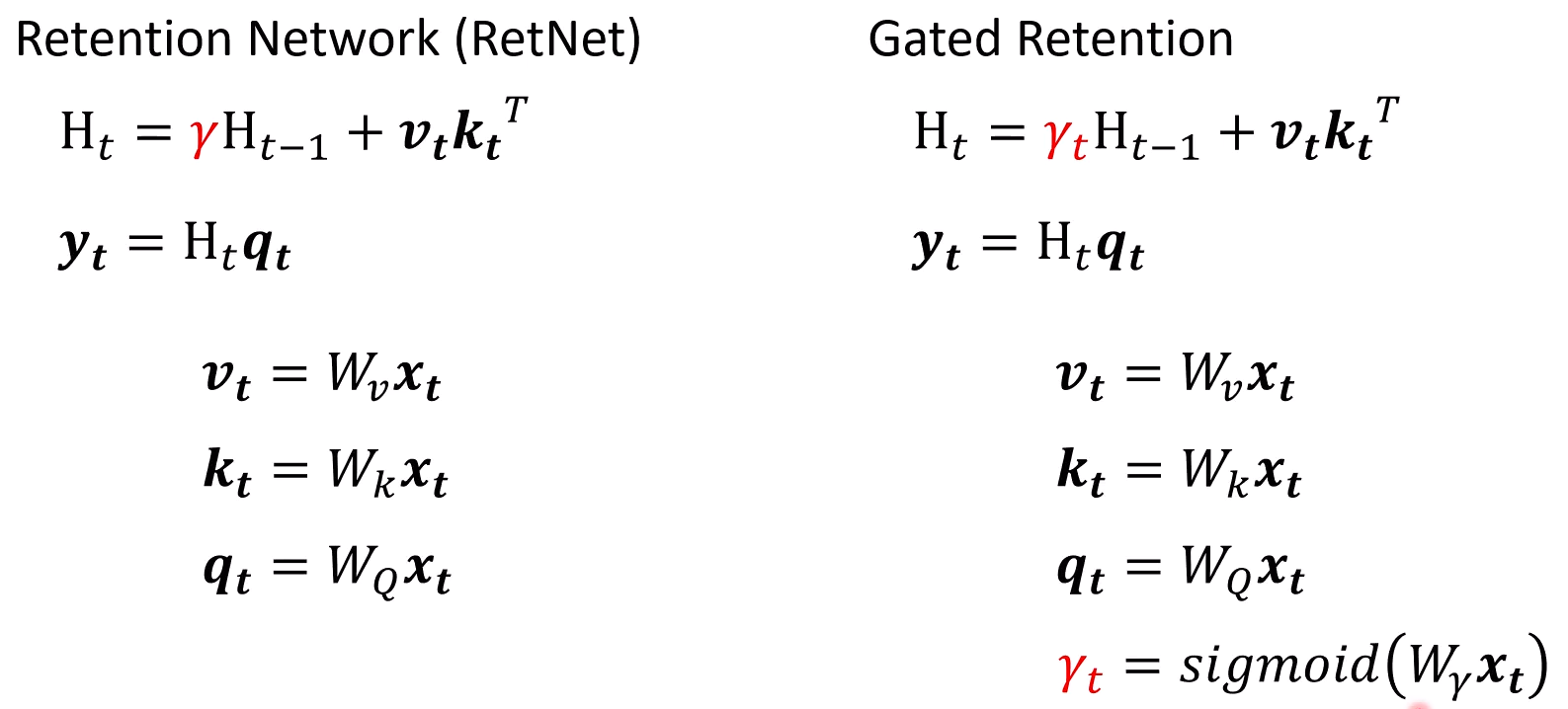
-
Gradient Descent
把即将存入的memory的信息中包含过去信息的部分减去

-
 WeChat Pay
WeChat Pay