论文 · REACT: SYNERGIZING REASONING and ACTING in LANGUAGE MODELS
Contents
基础信息
- 期刊 ICLR 2023
学习内容
-
文章是哪个领域的?研究什么具体问题?
ReAct:是把“语言化思考(Thought)”也当作 Agent 可以采取的一类动作。
如何让 LLM 在需要外部交互的任务中,同时发挥推理能力与行动能力,而非只做静态思维或盲目行动。
-
作者对已有方法的问题或当前挑战的分析?
- CoT(Chain of thought):会推理,但是知识来自内部,不能主动外部验证。(相对静态推理)
- Act-only:会用工具,但推理差。例如在厨房环境里,模型可能已经搜过某处没有胡椒瓶,却仍反复去那里拿胡椒瓶;它没有把“这里没有”抽象成可指导后续行动的结论。
-
文中提出解决问题的方法或主要贡献或创新?
- Thought:
- 计划
- 状态更新
- 错误恢复
- 子目标切换
- 行动选择
- 强调闭环,而不是一次性生成
- ReAct 的 Thought 不一定等于模型真正的内部因果过程,但它让开发者至少能检查:
- 它为什么搜这个词
- 它从观察中读到了什么
- 是检索失败、理解失败,还是执行失败
- 可以在哪一步插入人工修正
- Thought:
-
效果如何?
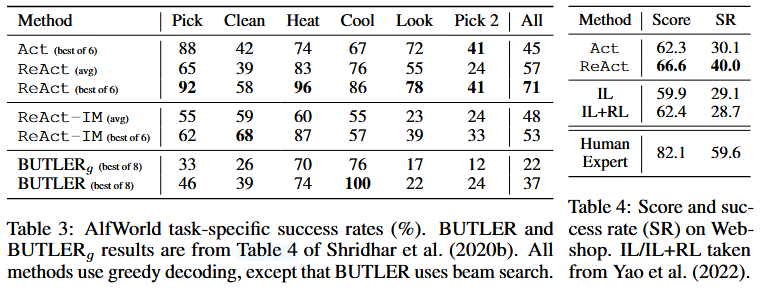
在 FEVER 上:
- CoT:56.3%
- Act:58.9%
- ReAct:60.9%
- CoT-SC -> ReAct:64.6%
-
优缺点和未来工作?
- 缺点:
- 模型写出的 Thought 是可读的行为记录,不一定就是模型内部真正的决策因果链。
- ReAct 会重复生成先前的 Thought 和 Action,难以跳出循环
- 若搜索结果为空、实体消歧失败或证据不相关,模型不容易恢复
- 任务越复杂、工具越多,演示样例就越长,容易碰到上下文长度限制
- 缺点:
 WeChat Pay
WeChat Pay