论文 · AGENTBENCH: EVALUATING LLMS as AGENTS
基础信息
- 期刊 ICLR 2024
学习内容
-
文章是哪个领域的?研究什么具体问题?
领域是:LLM Agent 智能体评测
传统 benchmark 多测“模型会不会答题”;AgentBench 测的是“模型能不能观察环境、规划下一步、调用动作、根据反馈继续行动,直到把任务做完”。
本文LLM Agent 看成一个多轮交互系统:用户目标→LLM 推理→动作→环境反馈→下一轮推理
用 POMDP 来形式化这个过程:环境有状态、模型只能看到部分观察、选择动作后环境改变,并得到奖励或任务结果。
核心评估点:
-
能否持续理解任务;
-
能否遵守动作格式;
-
能否在环境反馈后调整策略;
-
能否在长轨迹中保持目标;
-
能否真正完成任务,而非只生成看似合理的文本。
-
-
作者对已有方法的问题或当前挑战的分析?
-
一些benchmark 是静态题目
模型只要一次生成答案即可,不需要实际执行、观察反馈或修正错误,所以无法测出 Agent 最关键的多轮决策能力。
-
早期文本游戏的动作空间太封闭
文本游戏的动作少,更类似于分类学习和策略学习,和开放任务不一样
-
已有 Agent benchmark 往往只测单一环境
需要在不同操作系统或者不同数据库等环境下的稳定。
-
-
文中提出解决问题的方法或主要贡献或创新?
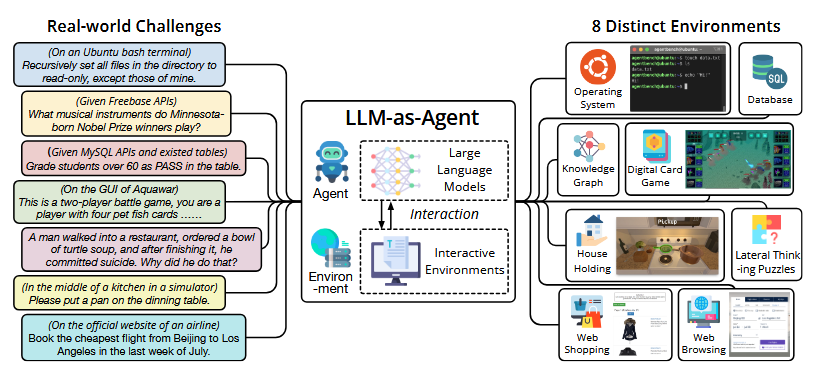
- 使用真实生活的问题挑战
- 模拟出8个环境来测试
类型 环境 主要能力 code Operating System Bash操作、文件系统 code Database SQL查改 code Knowledge Graph 调用工具、规划、信息检索 code Digital Card Game 策略、规则理解、决策 code Lateral Thinking Puzzles 发散推理、持续提问 code House Holding 常识、物体操作、长程规划 Web Web Shopping 搜索、筛选、购买决策 Web Web Browsing 网页上的操作 -
评价标准
在不同环境的指标不同。
-
效果如何?
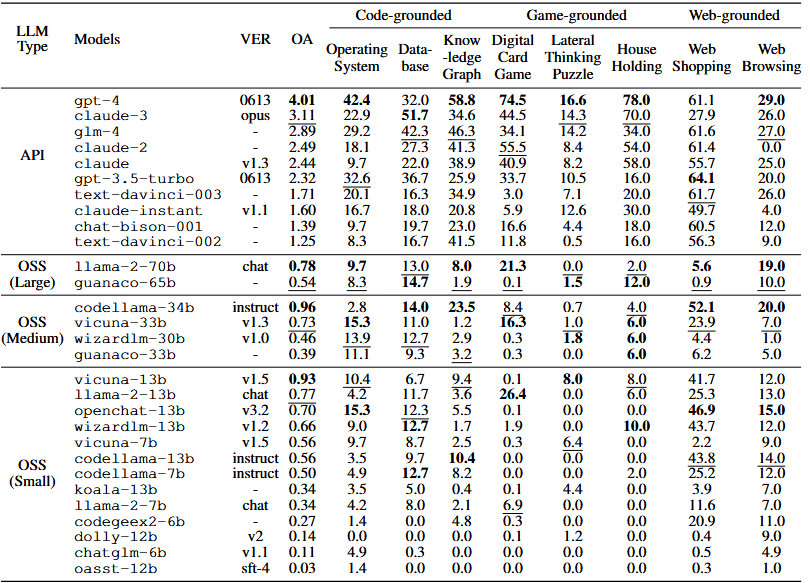
GPT-4 等头部商业模型明显领先开源模型,但仍频繁出现长程任务超限、动作无效、格式不遵循等失败;任务限额超限是最主要失败原因。
-
推论
-
高质量、多轮、面向指令遵循的对齐数据对 Agent 能力很关键。
-
代码训练似乎能帮助模型处理更流程化、步骤较固定的任务
例如 Web Shopping;但在需要更灵活策略或与环境持续交互的任务中,CodeLlama 并不一定更强,例如卡牌游戏、操作系统环境。
-
LLM作为Agent失败的类别:
- 完成:正常完成任务。
- Context Limit Exceeded:上下文过长
- Invalid Format:不按规定格式输出
- Invalid Action:格式正确,但动作不合法
- Task Limit Exceeded:到最大轮数还没做完,或者陷入重复(最主要失败原因)
-
-
优缺点和未来工作?
-
缺点:
-
环境仍然是模拟环境或受控基准
真实环境会有权限、延迟、异常页面、对抗内容和安全风险。
-
只评测基础 CoT Agent
不加入反思、搜索、记忆、规划器、多 Agent 协作等机制。只测试“基础模型 + 简单提示”的能力,不是现代完整 Agent 系统的上限。
-
Overall Score 不是绝对客观
-
模型结果具有时间性
-
-
未来工作
提升 Agent 不应只靠扩大模型或增强代码能力,还应重点改善多轮对齐、指令遵循、状态追踪、规划与纠错能力。
-
 WeChat Pay
WeChat Pay