NLP · 文本表示
本文参考b站视频教程学习
分词+词表构建
基础概念
流程:语料(Corpus)—> 分词(Tokenization)—> 词汇表(Vocabulary)
- 分词是将原始文本切分为若干个具有独立意义的最小单元(token)的过程
- 词表是为每个token设置 唯一确定的id,id和token之间可以双向映射
后续的训练/预测过程
语料(Corpus)—> 分词(Tokenization)—> 词汇表(Vocabulary)—> token的ID进入嵌入层(embedding layer),转为低维稠密的向量表示(词向量)—> 隐藏层—> 输出(神经元)
分词
对于不同的语言,由于语言结构和词边界的差异,分词策略和算法会不同
英文分词
按分词粒度的大小分类分词方法
-
词级分词 World Level
- 主要思想:最原始的分词方法,以空格标点为标志分词
- 优点:简单
- 缺点:容易出现OOV(Out-Of-Vocabulary,未登录词)问题,即文本中出现词表外的词
- 出现OOV后模型会对这些词换为统一的特殊标记(eg. < UNK >),从而导致语义信息的丢失,影响模型的理解和预测
-
字符级分词 Character-Level
-
主要思想:每一个字母、数字、标点、空格都被当做独立的token
-
优点:词表规模很小,覆盖率高,几乎不可能OOV
-
缺点:模型需要更长的上下文推断词义和结构,显著增加建模难度和成本。同时,输入序列边长,影响模型效率
-
-
子词级分词 Subword-Level
介于词级和字符级,英文分词最常用 eg. GPT、BERT
看具体效果网站:Tiktoken
- 主要思想:语料 -> 子词 -> token ,只要一个词能被拆分为词表中存在的子词单元(eg. 词根、前缀、后缀)就可以被模型识别和表示
- 优点:不会直接把所有的词表外的词做特殊标记
- 常见子词分词算法:BPE(Byte Pair Encoding),WordPiece,Unigram Language Model
- BPE:训练–把语料的词汇拆分为单个字符构建初始词表;迭代统计预料中出现频率最高的相邻字符对,将其合并为新子词单元,加入词表,持续这个过程到词表到Maxsize;分词–会对构建好的词表和合并规则对新的输入文本处理–文本拆分为最小单元,按顺序应用训练中学习到的合并规则,逐步合并到无法继续–得到分词结果。
中文分词
-
字符级分词
- 主要思想:以独立的每个汉字视为独立的token
- 特点:因为每个汉字有独立的意思,所以比起英文,中文不易OOV
-
词级分词
- 主要思想:中文文本按完整词语切分,切分结果贴近人阅读
- 特点:没有天然词边界,一般依赖于词典、规则、模型来识别词边界
-
子词级分词(eg. Deepseek、千问)
- 主要思想:类似英文,学习语料中高频的字组合,构建子词词表。
- 特点:无需人工词典,自适应能力强
分词工具
-
中文分词工具分类:
- 基于词典或模型的传统方法:以词为单位切分(eg. jieba, HanLP)
- 基于子词建模算法(eg. BPE, Hugging Face Tokenizer, SentencePiece, tiktoken):常用于大规模预训练语言模型
-
jieba分词器
-
精确模式:最精确的切开句子,适合文本分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17import jieba text = "我毕业于清华大学的计算机系" words_generator = jieba.cut(text) # 若改为lcut则是返回列表,cut是生成器 for word in words_generator: print(word) ''' 我 毕业 于 清华大学 的 计算机系 ''' -
全模式:把所有可以成词的词语扫描出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24import jieba text = "我毕业于清华大学的计算机系" words_generator = jieba.cut(text, cut_all=True) for word in words_generator: print(word) ''' 我 毕业 于清华 清华 清华大学 华大 大学 的 计算 计算机 计算机系 算机 系 ''' -
搜索引擎模式:精确模式基础上进一步对长词切分,适用于搜索引擎分词
-
自定义词典:用户可以自定义词典,包含jieba词库没有的词,用于增强特定领域词汇识别
(每行格式:词语-词频-词标签)
1 2 3 4 5 6 7 8 9 10 11 12 13import jieba jieba.load_userdict('dict.txt') word_list = jieba.lcut("黄狸花猫和白狸花猫都是狸花猫的一种类型,但是彩狸花猫是相比于黄狸花猫和白狸花猫在猫界中更受猫儿的欢迎的类型,是狸花猫里的大美女") print(word_list) ''' 不加词典 ['黄狸', '花猫', '和', '白狸', '花猫', '都', '是', '狸', '花猫', '的', '一种', '类型', ',', '但是', '彩狸', '花猫', '是', '相比', '于', '黄狸', '花猫', '和', '白狸', '花猫', '在', '猫界', '中', '更', '受', '猫儿', '的', '欢迎', '的', '类型', ',', '是', '狸', '花猫', '里', '的', '大美女'] 加词典 ['黄狸花猫', '和', '白狸花猫', '都', '是', '狸花猫', '的', '一种', '类型', ',', '但是', '彩狸花猫', '是', '相比', '于', '黄狸花猫', '和', '白狸花猫', '在', '猫界', '中', '更', '受', '猫儿', '的', '欢迎', '的', '类型', ',', '是', '狸花猫', '里', '的', '大美女'] '''
-
词表示
token => 计算机可操作的数值形式
发展:one-hot编码(稀疏)=> 语义化词向量(稠密)
One-hot编码
- 主要思想:词汇表中的每个词映射为一个稀疏向量(二维数组:行列数值为向量大小),向量长=词表大小,该词在对应位置为1
- 优点:简单直观
- 缺点:无法体现词和词的语义关系;并且词表越大
语义化向量
每个词生成一个具有语义意义的稠密向量表示,让向量能够在连续空间中表达此与词之间的关系,“意思相近”的词在空间中距离更近。
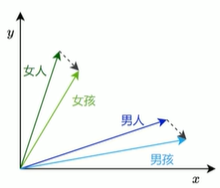
-
Word2Vec
一个词的含义由它周围的词决定(分布假设)
-
模型
-
CBOW(Continueous Bag-of-Words)模型
前后若干个词预测中间的目标词
如图,前向传播过程:
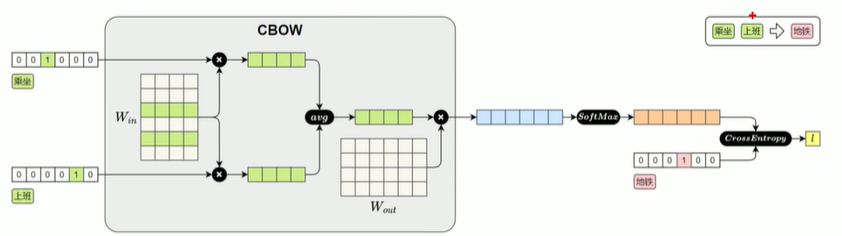
做反向传播,更新的值为W_in绿色两行
-
Skip-gram模型
从中心词预测上下文的词
滑动窗口确定中间的词为中心词(输入),两边的词为要推理的(输出),以此训练。
如图,前向传播过程:
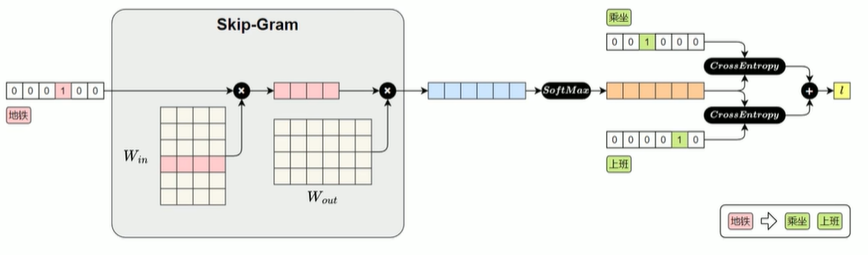
CrossEntropy函数:多分类(一个词找到多个词)
SoftMax函数:转化为概率分布
做反向传播更新的值是W_in粉色两行
-
-
原理
-
数据集:不用人工标注,直接可以用大规模原始文本作为数据源
-
流程:
语料 => 分词=>one-hot编码=>Skip-Gram
-
-
Word2Vec应用(eg. Gensim–Generate Similarity)
-
公开数据集(Chinese-Word-Vectors)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19from gensim.models import KeyedVectors model_path = './data/sgns.weibo.word.bz2' model = KeyedVectors.load_word2vec_format(model_path) print(model.vector_size) #看维度 print('\n') print(model['地铁']) # 查向量 print('\n') # 查相似度(两个向量的余弦值[-1,1]) similarity = model.similarity('地铁','公交') print('地铁和公交相似度:',similarity) print('\n') #找与某个词最相似的词 similar_words = model.most_similar(positive=['上班'], topn=5) print(similar_words) print('\n') -
个人数据集/词向量
1 2 3 4 5 6 7 8 9 10 11 12 13# gensim 不能分词 需要自己提前分 from gensim.models import Word2Vec sentences = [['我','每天','乘坐','地铁','上班'],['我','每天','乘坐','公交','上班']] model = Word2Vec( sentences,# 已分词序列 vector_size=100,# 词向量维度 window=5,# 上下文窗口大小 min_count=2,# 最小词频(低于的词背忽略) sg=1,# 1是skip-gram,0是CBOW workers=4 )
-
-
 WeChat Pay
WeChat Pay